


【中睿行业分享】浅谈人工智能产业趋势

免责声明:本文内容仅供读者参考,不作为任何投资建议;股市有风险,投资需谨慎。
一、行业概念
人工智能的本质:
对于终端而言,人工智能的本质是提高了生产效率。
而劳动力市场由供需决定,其供给端的因子为:
总劳动力 = 劳动人口总数 × 平均劳动效率
通用人工智能的推出,对平均劳动效率的拉动是非线性,且指数级倍数计算,直接对应的结果是总劳动力在短时间内产能爆发,人类文明的每一次快速发展都伴随生产效率的爆发,可以说,人工智能是正在发生的工业革命。
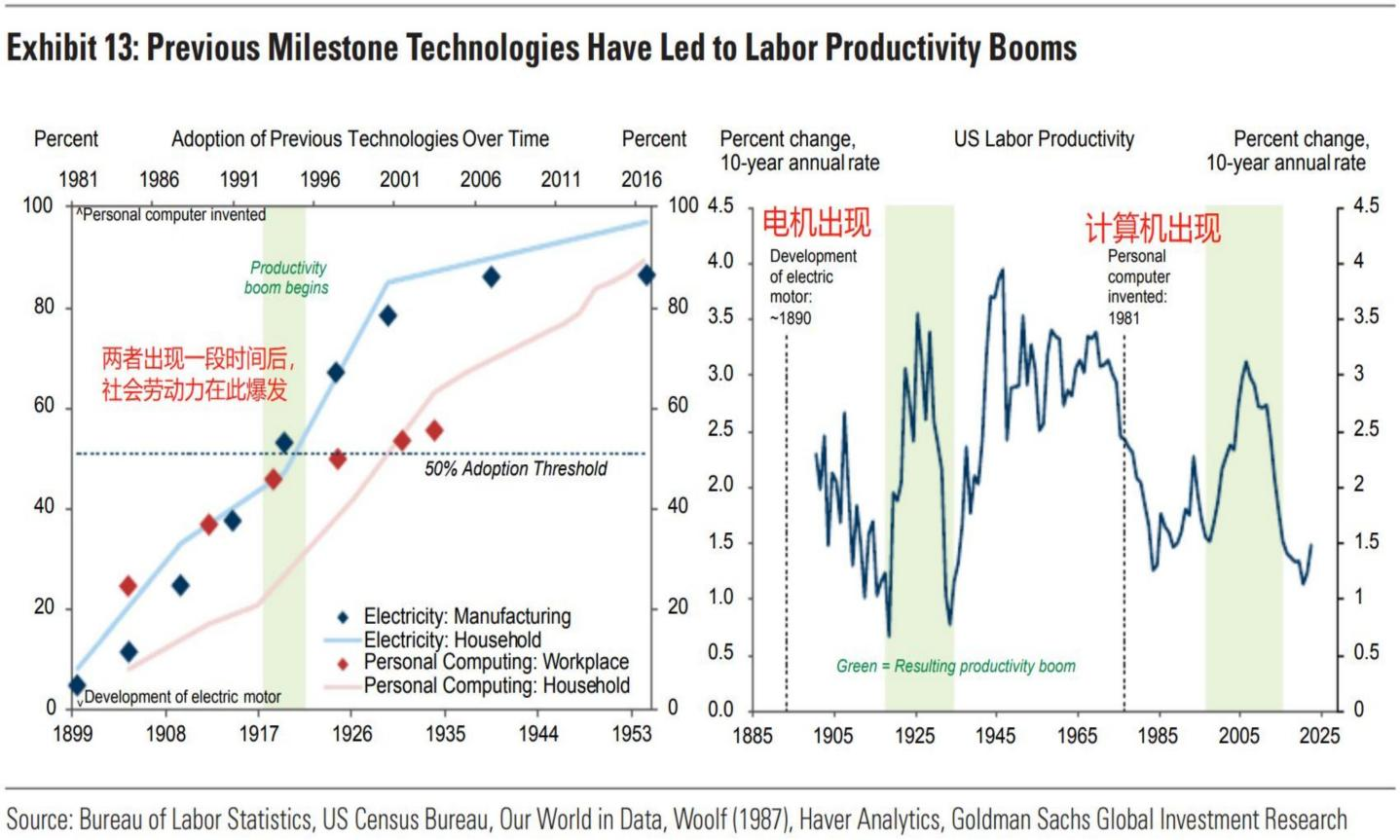
理解了上述背景以后,我们再进一步剖析算力的本质:
1)作为这一次提升生产效率的革命者,劳动力市场的需求端并没有消失,而只是对供给进行了冲击,无论ChatGPT以何种形式、在哪个领域突破,它要替代劳动力,就必须用更大单位的算力作制程,归因到最前端,本质是算力在替代劳动力;
2)算力的需求提升是非线性的,因为大模型的参数在每一次迭代后都增加N个数量级,但受制于硬件瓶颈(摩尔定律),算力的供给只可能是相对线性的,这就导致了算力的供需失衡。
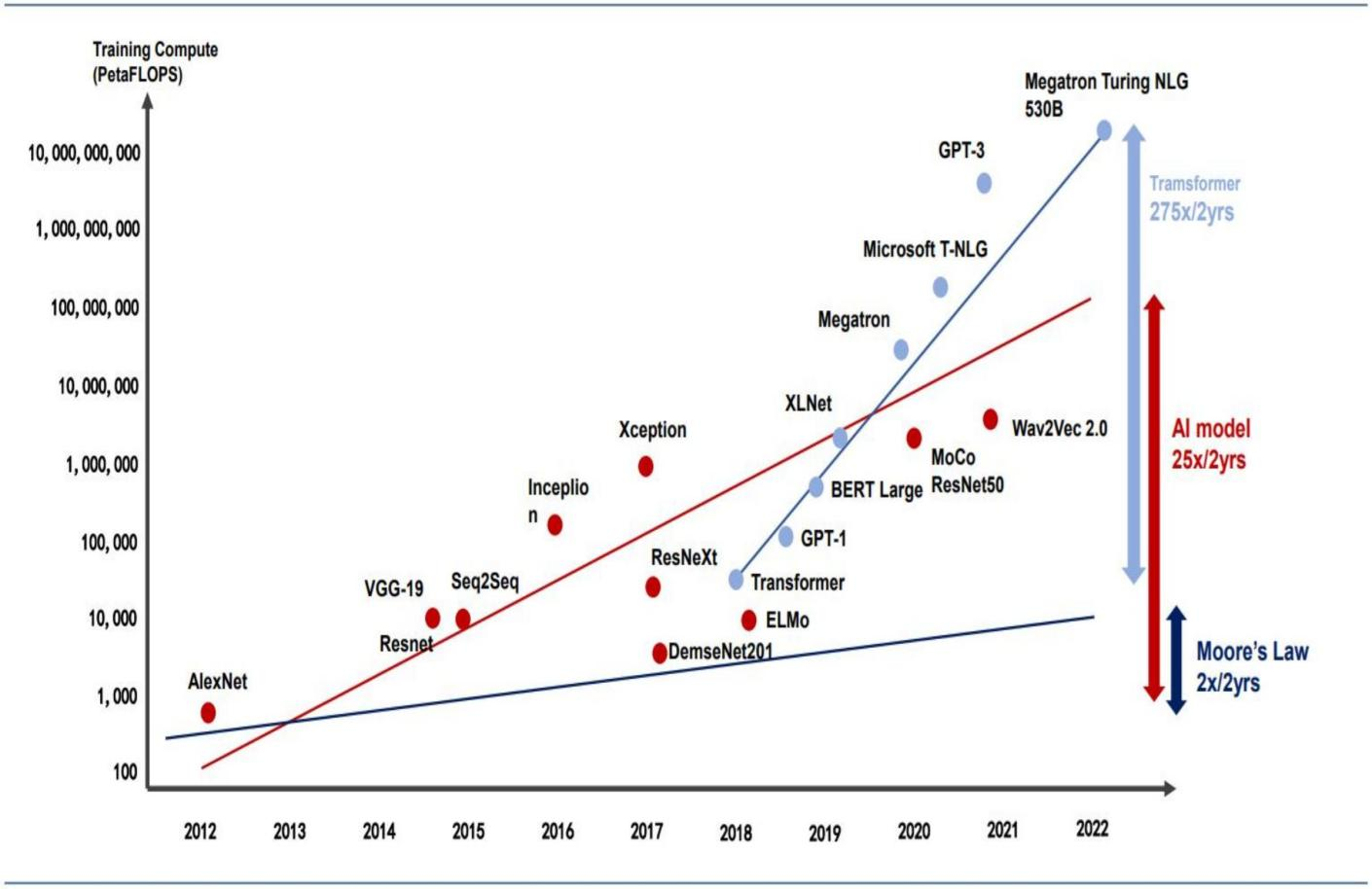
量化数据方面,以目前最标准的英伟达A100算力卡为例,在单一AI大模型的参数数量为1750亿时,1个模型需1080张A100显卡(单价15万元)。
随着GPT的进一步迭代,参数数量非线性提升,随着各大互联网厂商涌入大模型,整个算力卡的需求迎来井喷式爆发:
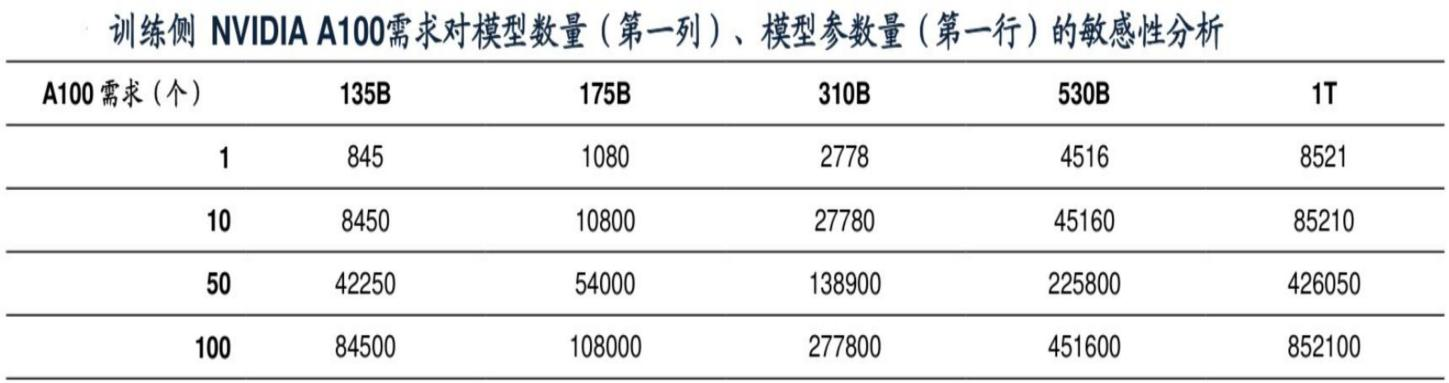
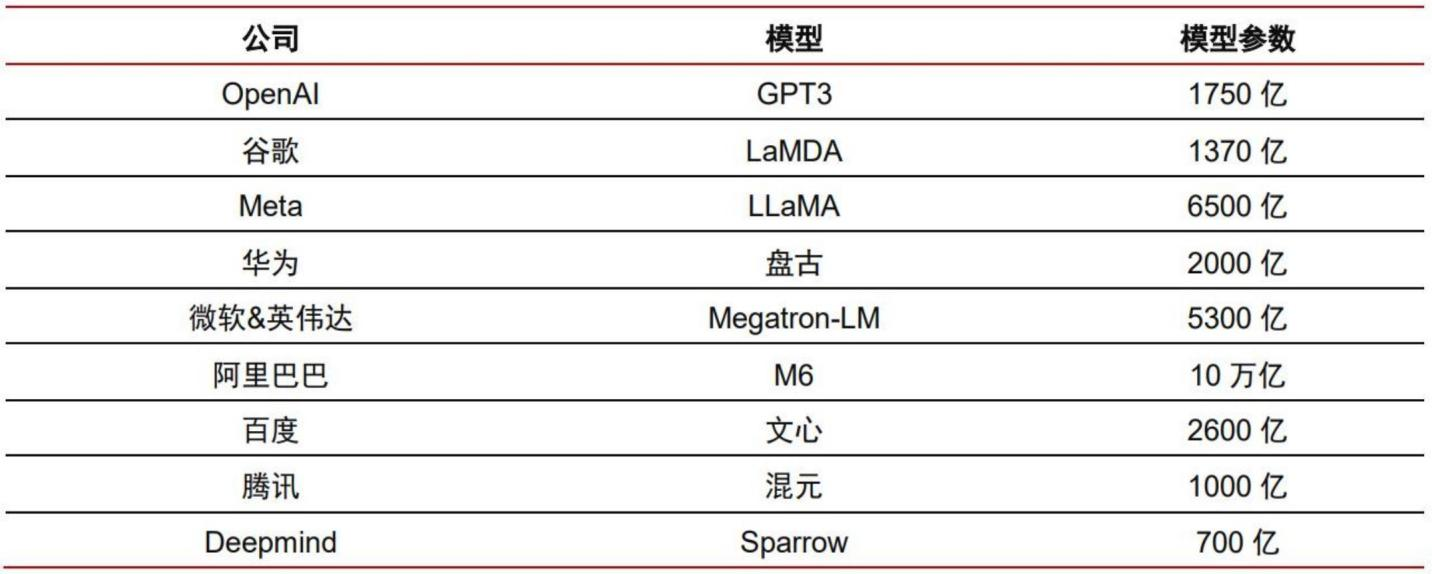
而GPT-3这个模型是比较低阶的,基本等于没法用的状态,
GPT-3.5还行但错误率还是比较高,
GPT-4算是目前相对而言最好的大模型之一,他的参数有上万亿个,是GPT-3的572倍,
随着AI大模型的继续迭代,模型参数的数量提升看不到尽头:

以上全部是训练侧的数据,也就是前期的准备阶段,每迭代一次模型,就要重新训练1次,以及训练1次(几十天)所需要的算力卡。
也就是说我们不考虑互联网大厂抢时间这个因素,这个阶段的产品是纯资本开支没有任何收入。
人工智能大模型的工作方式类似函数,上述训练完成一个公式之后,才会进入正式的使用阶段,即提出需求、解决需求的实操过程,我们称其为推理。
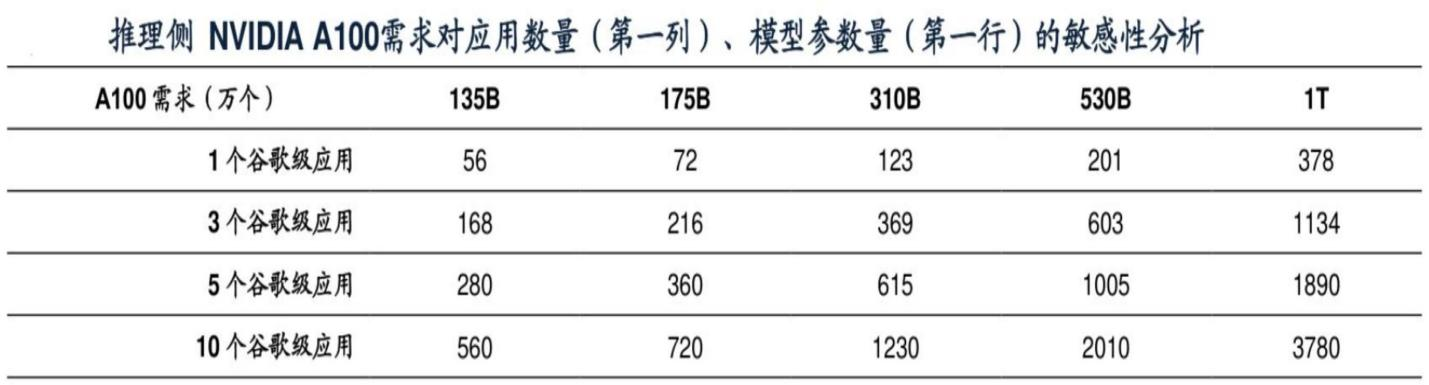
而在训练完成后才真正进入商用阶段, 即推理测。按现在的数据,推测1个应用需要的英伟达A100数量为378个(GPT4),而应用的数量会远高于大模型的数量。
比如我们现在已经可以看到的十数款AI绘画,Wind 的Aliece等等,这些就属于1个垂直细分的应用,按照华为的说法,这些C端应用的占比大概在1%,将来还会有无数的工商业端垂直应用出现。
二、行业现状
算力的单位为FLOPS(floating point operations per second),即每秒所执行的浮点运算次数,前文提到GPU发明之初的本意是对图像进行渲染,而这个浮点就可以理解成我们屏幕中的像素点,目前的FLOPS 数量已经达到TB个(1T =1024G)。
根据前述的产业背景,人工智能算力的突破意味着生产力的大跃迁,其划时代程度不亚于工业革命,因此对各国而言是必争之地。
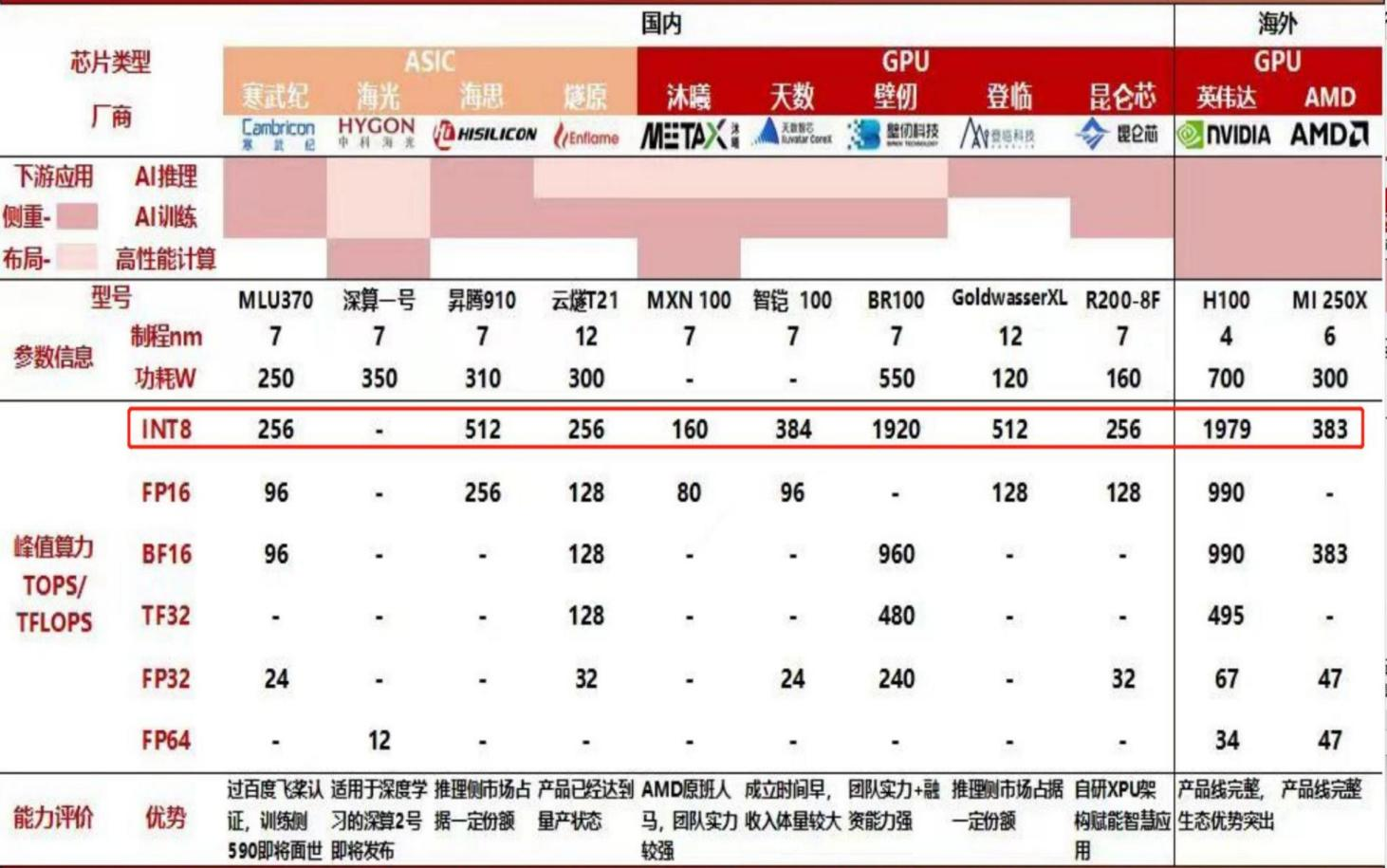
按目前最好的算力卡英伟达H100(台积电4/5nm工艺) 为基准进行衡量, NVDA、AMD和国内各大厂商最先进的产品算力情况如下:
相对而言,GPU的设计不算特别困难,芯片设计的目的是如何在单位面积内塞进更多的内核,同时保证能耗降到最低,这一点考验的还是设计能力。
从上表中不难看出,国内一级市场各个公司的团队其实都很厉害,不仅有本土的中科院团队(寒武纪),还有海外AMD原班人马的沐曦、在英伟达工作多年的壁仞等等,他们现在设计的芯片算力许多已经达到甚至超过了AMD。
以上是GPU的第一个壁垒,即设计难度高,但并非完全无法突破。
整个GPU的核心壁垒是在于生态,比如我们使用英伟达GPU进行模型训练时,需要“告诉“机器应该怎么做,这就涉及到编程语言。
英伟达在早年推出自家的CUDA,自此以后要想让GPU运算得最快,就必须要用 CUDA进行编程,刚开始时是只有英伟达显卡独家适配CUDA,反垄断以后开放给其他GPU芯片,但后面出现的问题是,CUDA始终每一个版本都会有bug,这个bug只有英伟达的芯片可以绕开,其他家的芯片无法绕开:
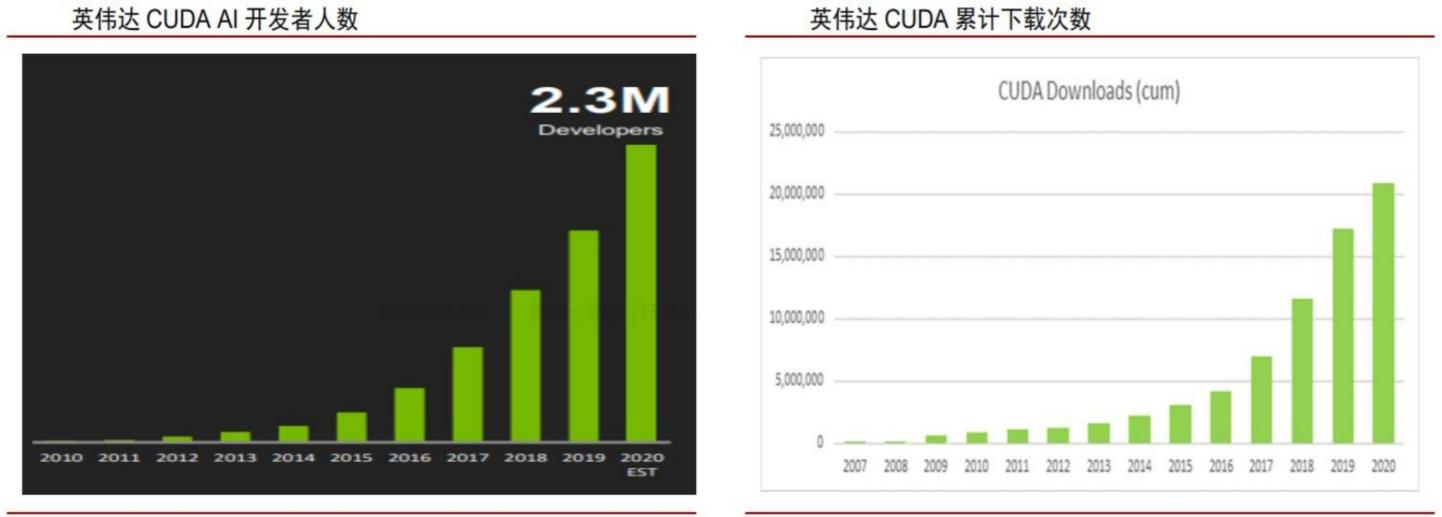
也就是说,英伟达的CUDA生态在GPU行业中已经不亚于PC上的windows操作系统,纵使各家在GPU上可以完成设计,但始终无法像英伟达自家显卡一样完美兼容CUDA,最终导致性能永远跟不上英伟达,而如果不兼容CUDA,自己开发生态,则又是一道需要从零开始的路径。
因此国产GPU厂家目前就出现了一些问题:
1)本就在初创阶段的企业,GPU设计人才在国内又属于高度稀缺 以沐曦为例 ,每年需要烧20亿+的研发和管理费用,在没有形成自己的生态之前,兼容CUDA的GPU毫无竞争力,导致营收远远匹配不上研发支出,只能靠融资,这一次遇到行业景气度下行之后,不少企业已经断了现金流。
2)不仅仅是沐曦一家企业出现这种情况,上表中除了国家队的寒武纪和海光信息有中科院养活,其余基本全 都面临这些情形,但客观来讲,这些团队的人才其实是目前国内最好的,这些企业的共同作用下,毫不夸张地说,国内商用端GPU厂商各自埋头搞自己的,就出现了一个比较尴尬的现状:
浪费行业人才资源、浪费资本,生态的建立并不是一年两年就能完成的,纯靠投资者融资烧钱,而且还几家一起没有尽头的烧,显然不可持续。
从上面的一系列情况可以看到,国产GPU要想破局,走兼容CUDA这条路是不可能的,否则未来某一天会通过CUDA制裁,因此我们只能开发出一套自己的生态。
这也就意味着,国内并不需要这么多的一级市场GPU厂商,当下的需要做的是对他们进行整合,集中人才资源、集中资本,把我们自己的生态做出来,而且当下面临的情形是这件事情不管是否能做成,也必须要一直不停地尝试。
二、行业趋势研判
ChatGPT3.5从2022年11月发布以来,在Google上的搜索量迅速提升,斜率非常夸张,和美国的国民电影星球大战一个级别,远远超出了当年苹果第一次发布ipad时的场景:
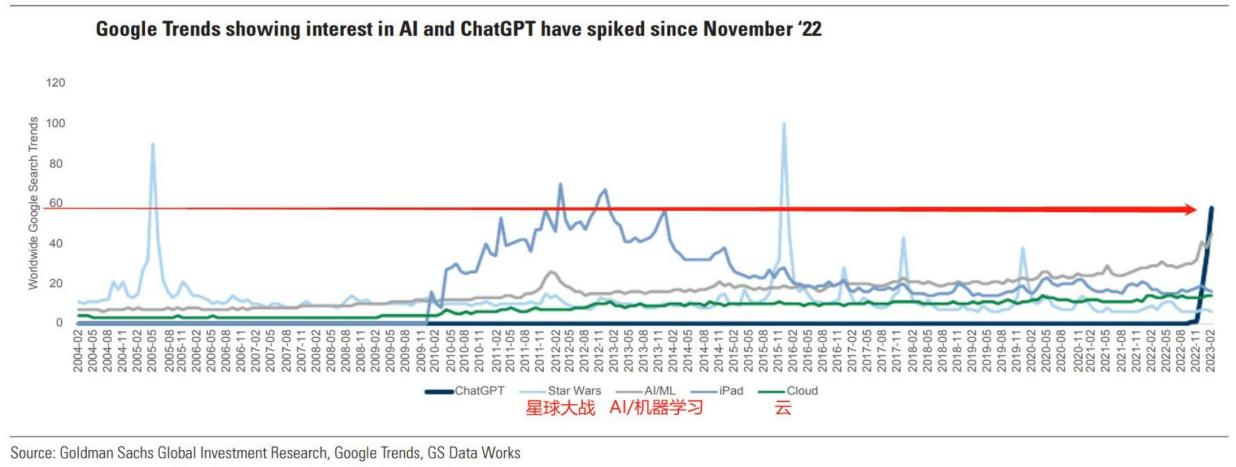
再结合GPT的月活数据来看,月活是相对滞后的指标,直到12月中旬开始才看到明显的趋势:
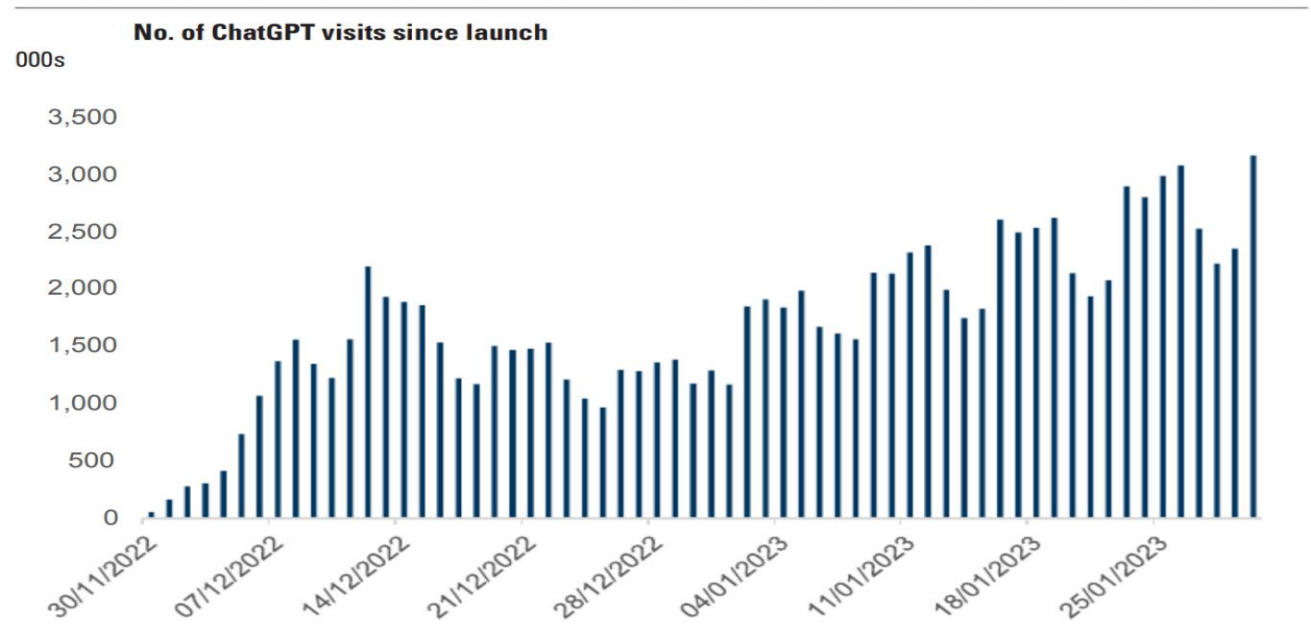
而这一次的产业浪潮由美国引领,与光伏电车不同,国内在所有的关键环节(模型、芯片、应用)都没有头部公司。
那么落到研究跟踪的角度,难度其实特别大,一方面缺乏基本的行业数据(产能数据、用户数据全部在外),另一方面产能也不在国内。
比如AI行情演绎至今,最高频的跟踪也只是每天早上起来看新闻,或者等海外企业的发布会。
这也就决定了,不管从产业实体层面,还是股价的表现层面,A股的人工智能在很大程度上都是被动的。
因此整个AI产业链中主要蕴含两类投资机会
1)第一类:
更偏海外产业链,找到英伟达/AMD股价的驱动力,然后去把握这种映射类的机会。
2)第二类:
主要聚焦在国内产业自身的变化上,比如我们自己的算力突破,自己的大模型突破,边缘侧国内出现爆款应用,股价演绎能够脱离美股龙头的细分,跟踪判断起来会相对更好上手一些。
按科技部规划,2025年由科技部主导的中国智能算力中心需要搭载1000EFLOPS的算力(要求国产算力占比超过50%、60%),而2022年底的数字为不到300E,整体复合增速水平达56.15%:
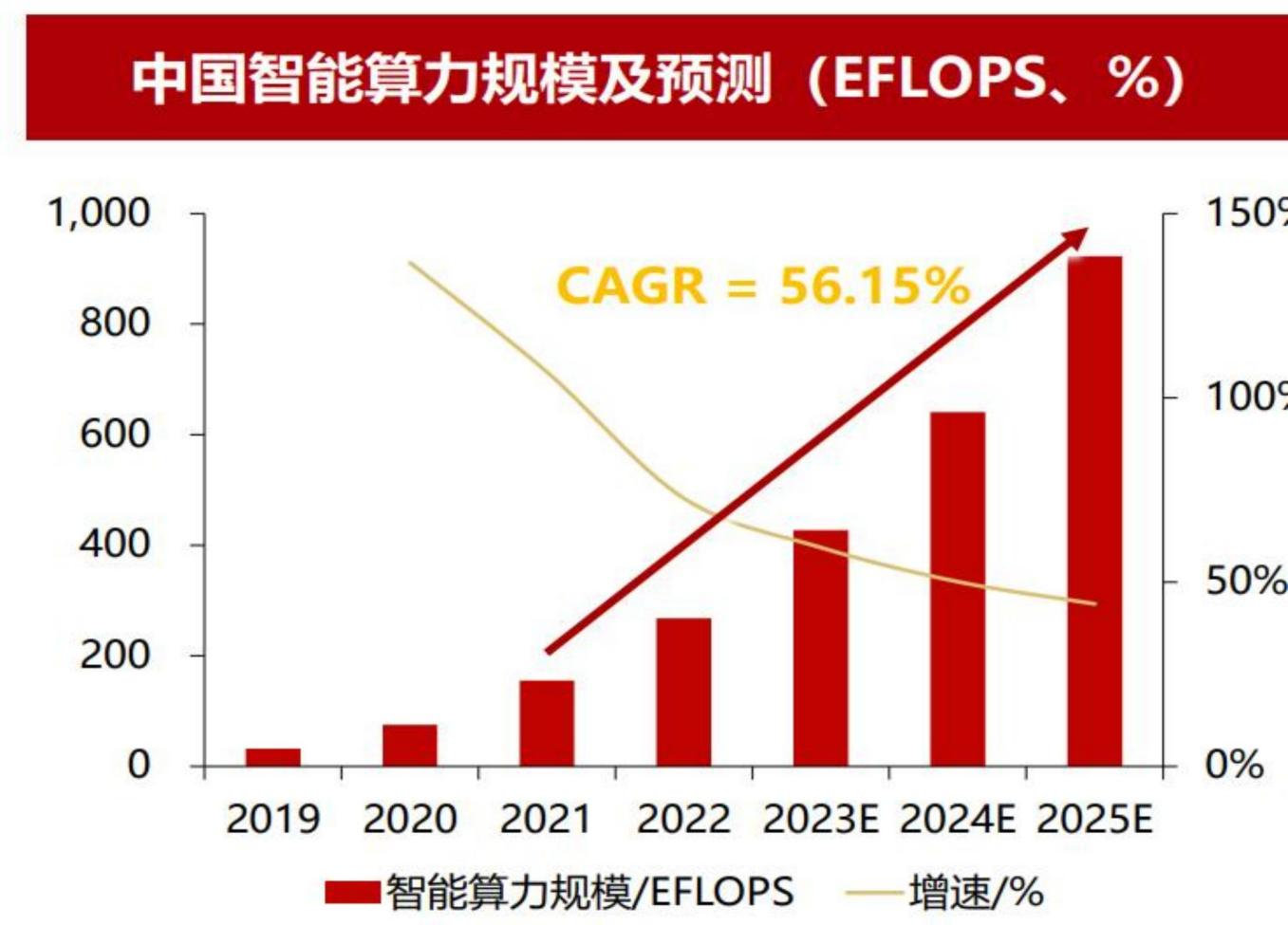
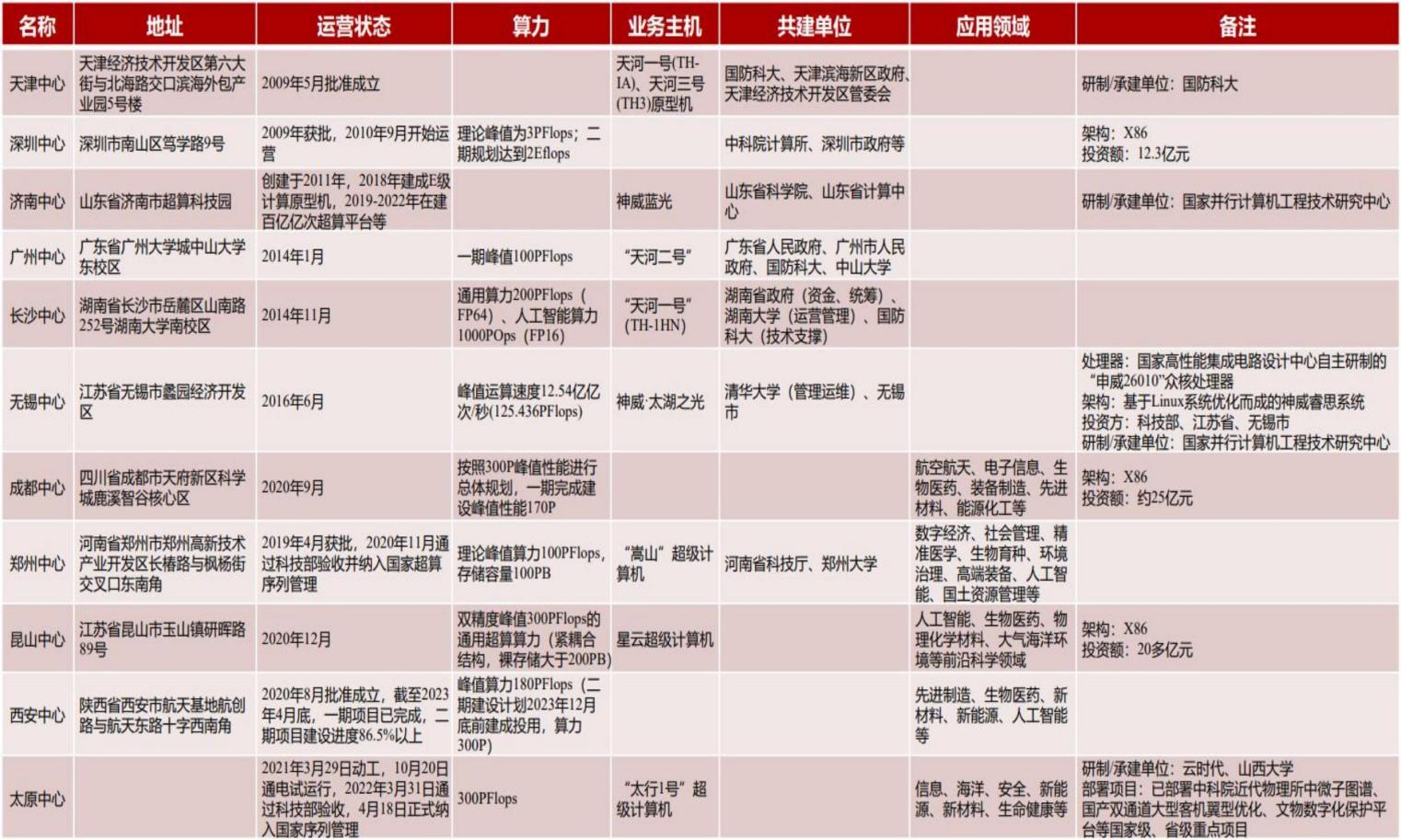
实际上地方政府也有自主意愿来配合算力中心的规划,因为一颗GPU上到服务器,再上云后,供下游互联网企业使用,再分发到B/C端GDP乘数超过10倍,从目前统计的情况来看,核心二线城市基本都已经出台了算力中心的规划:
四、观点分享
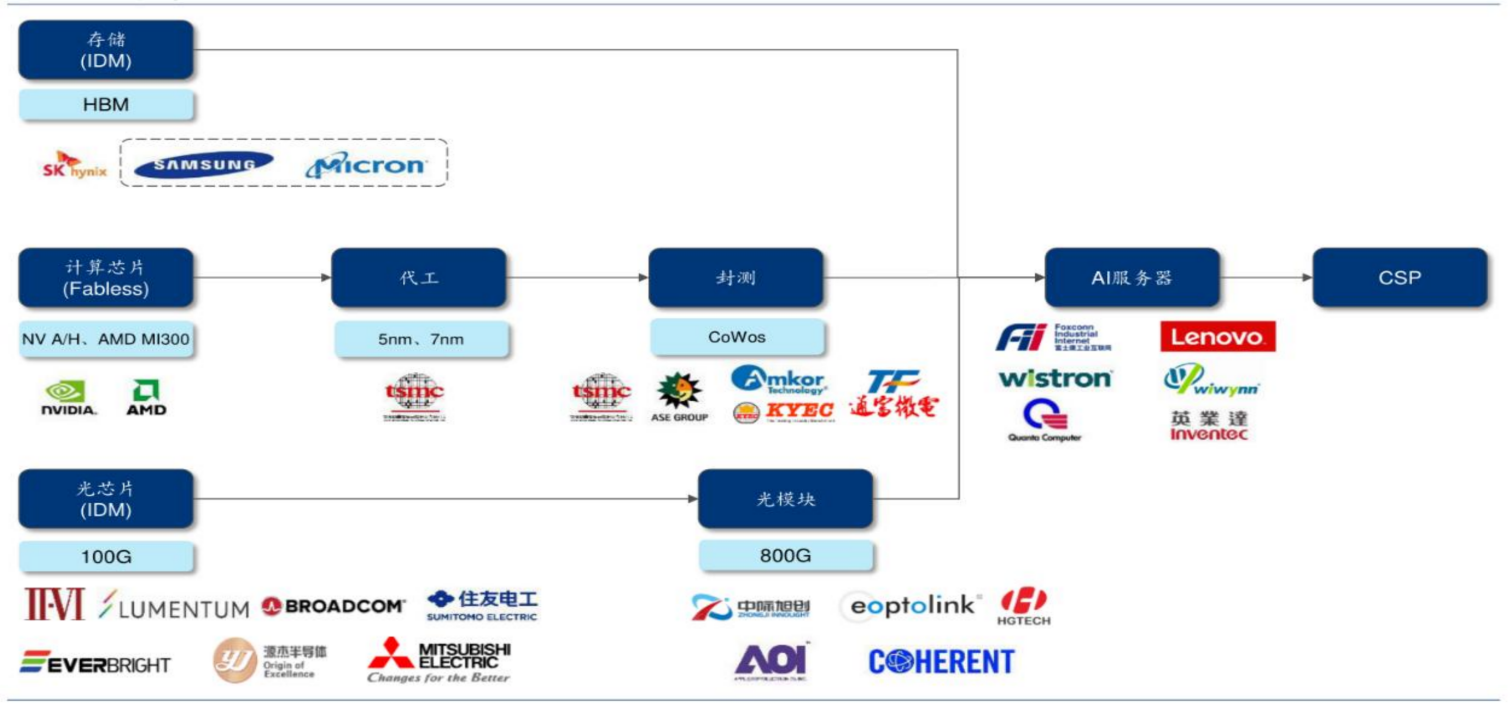
重点关注后续海外产业链1-10、国内产业链0-1的机会
免责声明:本报告中的信息所表述的意见并不构成对任何人的投资建议。任何情况下,本公司不承担以本报告为基础进行的任何投资活动所可能导致的风险。

